While as far back as the mid-1800s, textual critics had a natural sense of the value of the quantity as well as the quality of witnesses to the text, the concept wasn't put on firm mathematical ground until it was faced squarely by Wilber F. Pickering in his book, The Identity of the NT Text (Nelson, 1977/80), in an Appendix C, "The Implications of Statistical Probability...", actually written by Zane/David Hodges. This book is freely available for viewing and download on Pickering's site here. - (click to read).
There, Hodges argued that probability was decidedly in favor of the Majority text (the readings found in the majority of surviving manuscripts).
This was almost immediately challenged by D. A. Carson in his own appendix to The KJV Debate (Baker, 1979/80), a review of Pickering's book.
Although the original diagrams and equations are complex for ordinary readers, the gist of the argument can be simply illustrated as follows:

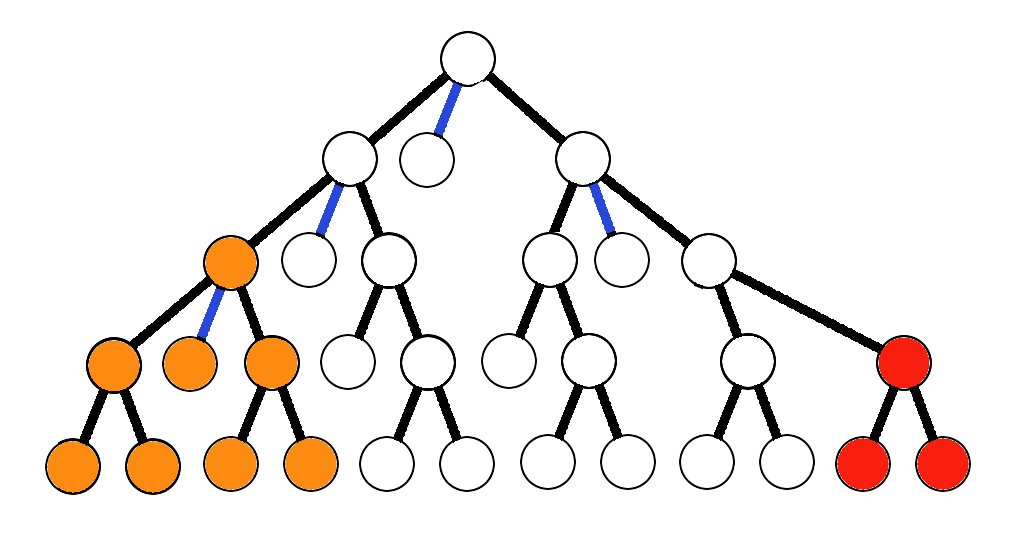
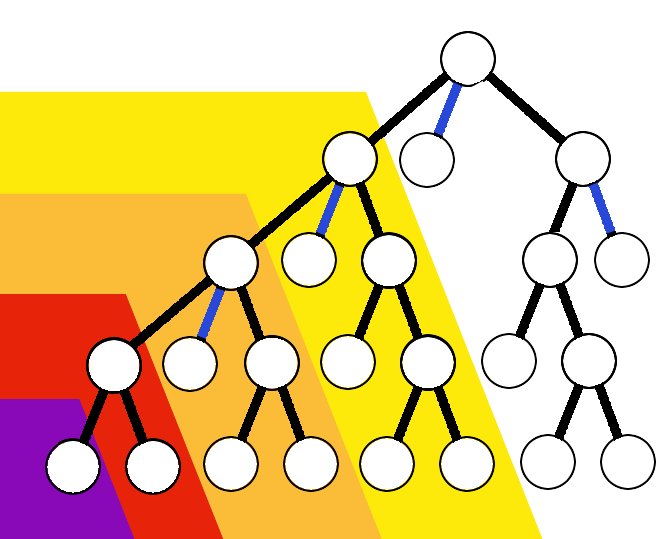
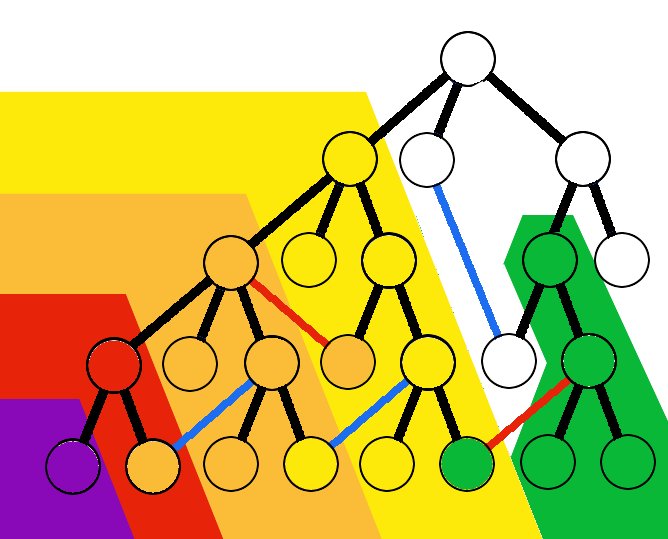
(1) If each manuscript is copied more than once, then there will always be more copies in each following generation. In the picture above, each row represents a copying generation, and the number of manuscripts doubles each generation. The copies form a simple, ever expanding genealogical tree, as in the diagram above.

(2) An error cannot be copied backward in time, so each error can only influence the copies which come after it, not those already written. Even the act of mixture cannot change this fundamental fact.
(3) The manuscripts with the given error will be in the minority. The later the error, the smaller the minority. Even just 2 or 3 generations later, errors quickly become clear minority readings. (The diagram above poses minimal reproduction, and a 3rd generation error is stuck with about 25% attestation. )

(4) Error accumulation is a self-limiting process, and later errors have little chance of influencing the text at all, even when preferred and adopted. For instance, by the 10th generation, it is impossible to introduce significant errors into the copying stream, even with minimal reproduction rates.
The basic assumptions of this model are that it is a reasonably "normal" copying process. Very little regulation is required for the model to be overwhelmingly accurate regarding the basic process of error accumulation. To be functional and predictive, the model only makes a few assumptions:
Critiques and objections to this model center around whether or not the transmission of the NT text really was "normal" in the sense described by the model. D. A. Carson's objection for instance, is based on three points:
(1) The probability argument, as already stated, is independent of the motives or causes of corruption. It is only a statement about the physical process itself.
This fact eliminates the basic objections found in (a).
(2) Far from contradicting the fact that most errors with significant attestation are early, the model actually predicts this. Scrivener and Colwell may have found it (psychologically) 'paradoxical' but a mathematician doesn't. The model is independent of objection (b) and (d). Even if more than one error at a time is introduced in each copy (very likely), this only means that each group of errors can be treated as a single corruption event or 'variation unit'. It makes no difference to the model, or its general predictions.
(3) If Carson is going to posit a 'catastrophic event' (like a major recension, and an accompanying slash and burn of all other contemporary copies), then he has to actually show historical evidence of such a historical event. Even a major recension cannot significantly alter the model, unless we add the destruction of most other unedited copies, and add the cooperation of all parts of Christendom (in the 4th century, the time when presumably this must placed), and also the large scale reproduction of the new substitute text. Neither Hort nor Carson have ever produced the historical evidence that such a catastrophic event took place.
(4) As to the 'carelessness' or lack of talent of early Christian scribes, this also has no effect on the model; it only affects the average rate of errors introduced to the text per generation. Carson has failed to grasp the essential features of the model of normal transmission, which is unaffected by varying rates of error.
We will show the true problems, and limits of the probability model in a second post.
(to be continued...)
peace
Nazaroo
There, Hodges argued that probability was decidedly in favor of the Majority text (the readings found in the majority of surviving manuscripts).
This was almost immediately challenged by D. A. Carson in his own appendix to The KJV Debate (Baker, 1979/80), a review of Pickering's book.
Although the original diagrams and equations are complex for ordinary readers, the gist of the argument can be simply illustrated as follows:
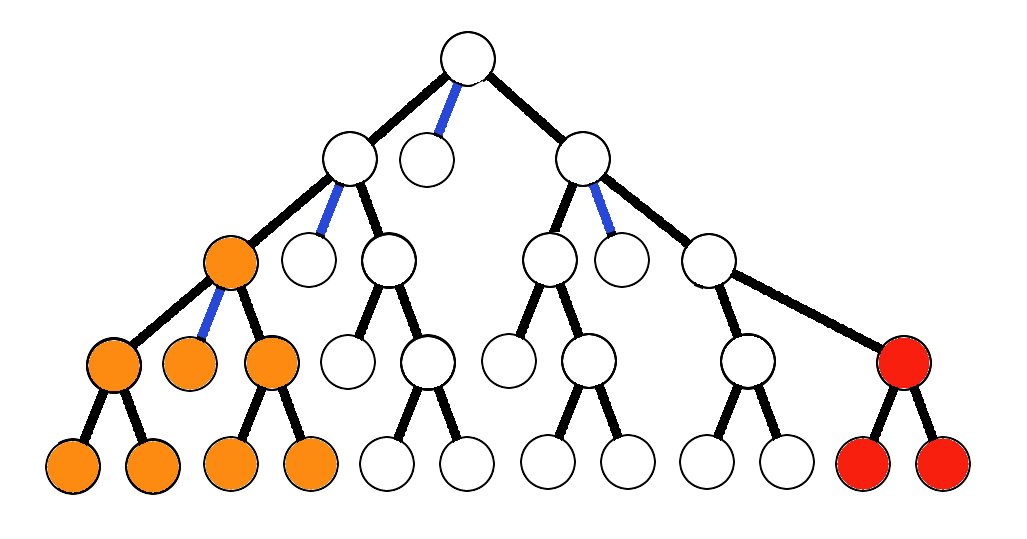
(1) If each manuscript is copied more than once, then there will always be more copies in each following generation. In the picture above, each row represents a copying generation, and the number of manuscripts doubles each generation. The copies form a simple, ever expanding genealogical tree, as in the diagram above.
(2) An error cannot be copied backward in time, so each error can only influence the copies which come after it, not those already written. Even the act of mixture cannot change this fundamental fact.
(3) The manuscripts with the given error will be in the minority. The later the error, the smaller the minority. Even just 2 or 3 generations later, errors quickly become clear minority readings. (The diagram above poses minimal reproduction, and a 3rd generation error is stuck with about 25% attestation. )

(4) Error accumulation is a self-limiting process, and later errors have little chance of influencing the text at all, even when preferred and adopted. For instance, by the 10th generation, it is impossible to introduce significant errors into the copying stream, even with minimal reproduction rates.
The Assumptions of the Model:
The basic assumptions of this model are that it is a reasonably "normal" copying process. Very little regulation is required for the model to be overwhelmingly accurate regarding the basic process of error accumulation. To be functional and predictive, the model only makes a few assumptions:
a) Most manuscripts should be copied more than once. It is not even necessary that all manuscripts be copied. The process is very robust and allows for a wide variation in rates and numbers.
b) The relative rates of copying should be moderately equal in each generation, for most branches. That is, one manuscript should not be copied too many more times than the others. Again the process is robust, and difficult to skew or break.
It is important to understand that this model of manuscript reproduction is just a scientific physical description, and completely neutral as to the causes of errors in the transmission stream. For this discussion, "error" does not signify any intent or lack of same on the part of the copyist or editor. It only signifies physical variance from the original text. The model is not influenced in the least by the motives of copyists or editors, and does not concern itself at all with how a variation in the text is introduced. It only makes universal assumptions about the mechanics of copying and errors in transmission. b) The relative rates of copying should be moderately equal in each generation, for most branches. That is, one manuscript should not be copied too many more times than the others. Again the process is robust, and difficult to skew or break.
Critiques and objections to this model center around whether or not the transmission of the NT text really was "normal" in the sense described by the model. D. A. Carson's objection for instance, is based on three points:
(a) Historical factors skewed the results, allowing the dominance of a less accurate text (the Byzantine). He cites (1) the influence of Chrysostom, (2) the restriction and displacement of the Greek language. Because of this he argues, the Byzantine text probably doesn't represent the original text.
(b) The 'generational' argument fails because errors were not introduced "generation by generation, but wholesale, in the first 2 centuries". Additionally, pressures to make the text uniform make the argument about most errors being minority readings null.
(c) Catastrophes during transmission negate the predictions. Carson uses the "flood" analogy to say that transmission trees can be 'restarted' from bad copies and previous evidence lost. Presumably then, observations cannot be extrapolated back to pre-catastrophe conditions.
(d) Early Christian copyists were inferior to Jewish scribes. Carson argues that therefore they were careless with the text. The majority of variants were early and accidental.
Carson's objections however, are essentially a failure.(b) The 'generational' argument fails because errors were not introduced "generation by generation, but wholesale, in the first 2 centuries". Additionally, pressures to make the text uniform make the argument about most errors being minority readings null.
(c) Catastrophes during transmission negate the predictions. Carson uses the "flood" analogy to say that transmission trees can be 'restarted' from bad copies and previous evidence lost. Presumably then, observations cannot be extrapolated back to pre-catastrophe conditions.
(d) Early Christian copyists were inferior to Jewish scribes. Carson argues that therefore they were careless with the text. The majority of variants were early and accidental.
(1) The probability argument, as already stated, is independent of the motives or causes of corruption. It is only a statement about the physical process itself.
This fact eliminates the basic objections found in (a).
(2) Far from contradicting the fact that most errors with significant attestation are early, the model actually predicts this. Scrivener and Colwell may have found it (psychologically) 'paradoxical' but a mathematician doesn't. The model is independent of objection (b) and (d). Even if more than one error at a time is introduced in each copy (very likely), this only means that each group of errors can be treated as a single corruption event or 'variation unit'. It makes no difference to the model, or its general predictions.
(3) If Carson is going to posit a 'catastrophic event' (like a major recension, and an accompanying slash and burn of all other contemporary copies), then he has to actually show historical evidence of such a historical event. Even a major recension cannot significantly alter the model, unless we add the destruction of most other unedited copies, and add the cooperation of all parts of Christendom (in the 4th century, the time when presumably this must placed), and also the large scale reproduction of the new substitute text. Neither Hort nor Carson have ever produced the historical evidence that such a catastrophic event took place.
(4) As to the 'carelessness' or lack of talent of early Christian scribes, this also has no effect on the model; it only affects the average rate of errors introduced to the text per generation. Carson has failed to grasp the essential features of the model of normal transmission, which is unaffected by varying rates of error.
We will show the true problems, and limits of the probability model in a second post.
(to be continued...)
peace
Nazaroo